TL;DR: dlt is a library for Normies: Problem solvers with antipathy for black boxes, gratuitous complexity and external dependencies.
This post tells the story of how we got here.
Try it in colab:
- Schema evolution
- Data Talks Club Open Source Spotlight + Video
- Hackernews Api demo
- LLM-free pipeline generation demo +4min Video
But if you want to load pandas dfs to production databases, with all the best practices built-in, check out this documentation or this colab notebook that shows easy handling of complex api data.
Or check out more resources at the end of the article
I. The background story: Normal people load data too
Hey, I’m Adrian, cofounder of dlt. I’ve been working in the data industry since 2012, doing all kinds of end-to-end things.
In 2017, a hiring team called me a data engineer. As I saw that title brought me a lot of work offers, I kept it and went with it.
But was I doing data engineering? Yes and no. Since my studies were not technical, I always felt some impostor syndrome calling myself a data engineer. I had started as an analyst, did more and more and became an end to end data professional that does everything from building the tech stack, collecting requirements, getting managers to agree on the metrics used 🙄, creating roadmap and hiring a team.
Back in 2022 there was an online conference called Normconf and I ‘felt seen’. As I watched Normconf participants, I could relate more to them than to the data engineer label. No, I am not just writing code and pushing best practices - I am actually just trying to get things done without getting bogged down in bad practice gotchas. And it seemed at this conference that many people felt this way.

Normies: Problem solvers with antipathy for black boxes, gratuitous complexity and external dependencies
At Normconf, "normie" participants often embodied the three fundamental psychological needs identified in Self-Determination Theory: autonomy, competence, and relatedness.
They talked about how they autonomously solved all kinds of problems, related on the pains and gains of their roles, and showed off their competence across the board, in solving problems.
What they did, was what I also did as a data engineer: We start from a business problem, and work back through what needs to be done to understand and solve it.
By very definition, Normie is someone not very specialised at one thing or another, and in our field, even data engineers are jacks of all trades.
What undermines the Normie mission are things that clash with the basic needs, from uncustomisable products, to vendors that add bottlenecks and unreliable dependencies.
Encountering friction between data engineers and Python-first analysts
Before becoming a co-founder of dlt I had 5 interesting years as a startup employee, a half-year nightmare in a corporation with no autonomy or mastery (I got fired for refusing the madness, and it was such a huge relief), followed by 5 fun, rewarding and adventure-filled years of freelancing. Much of my work was “build&hire” which usually meant building a first time data warehouse and hiring a team for it. The setups that I did were bespoke to the businesses that were getting them, including the teams - Meaning, the technical complexity was also tailored to the (lack of) technical culture of the companies I was building for.
In this time, I saw an acute friction between data engineers and Python-first analysts, mostly around the fact that data engineers easily become a bottleneck and data scientists are forced to pick up the slack. And of course, this causes other issues that might further complicate the life of the data engineer, while still not being a good solution for the data consumers.
So at this point I started building boilerplate code for data warehouses and learning how to better cater to the entire team.
II. The initial idea: pandas.df.to_sql() with data engineering best practices
After a few attempts I ended up with the hypothesis that df.to_sql() is the natural abstraction a data person would use - I have a table here, I want a table there, shouldn’t be harder than a function call right?
Right.
Except that particular function call is anything but data engineering complete. A single run will do what it promises. A production pipeline will also have many additional requirements. In the early days, we wrote up an ideal list of features that should be auto-handled (spoiler alert: today dlt does all that and more). Read on for the wish list:
Our dream: a tool that meets production pipelines requirements
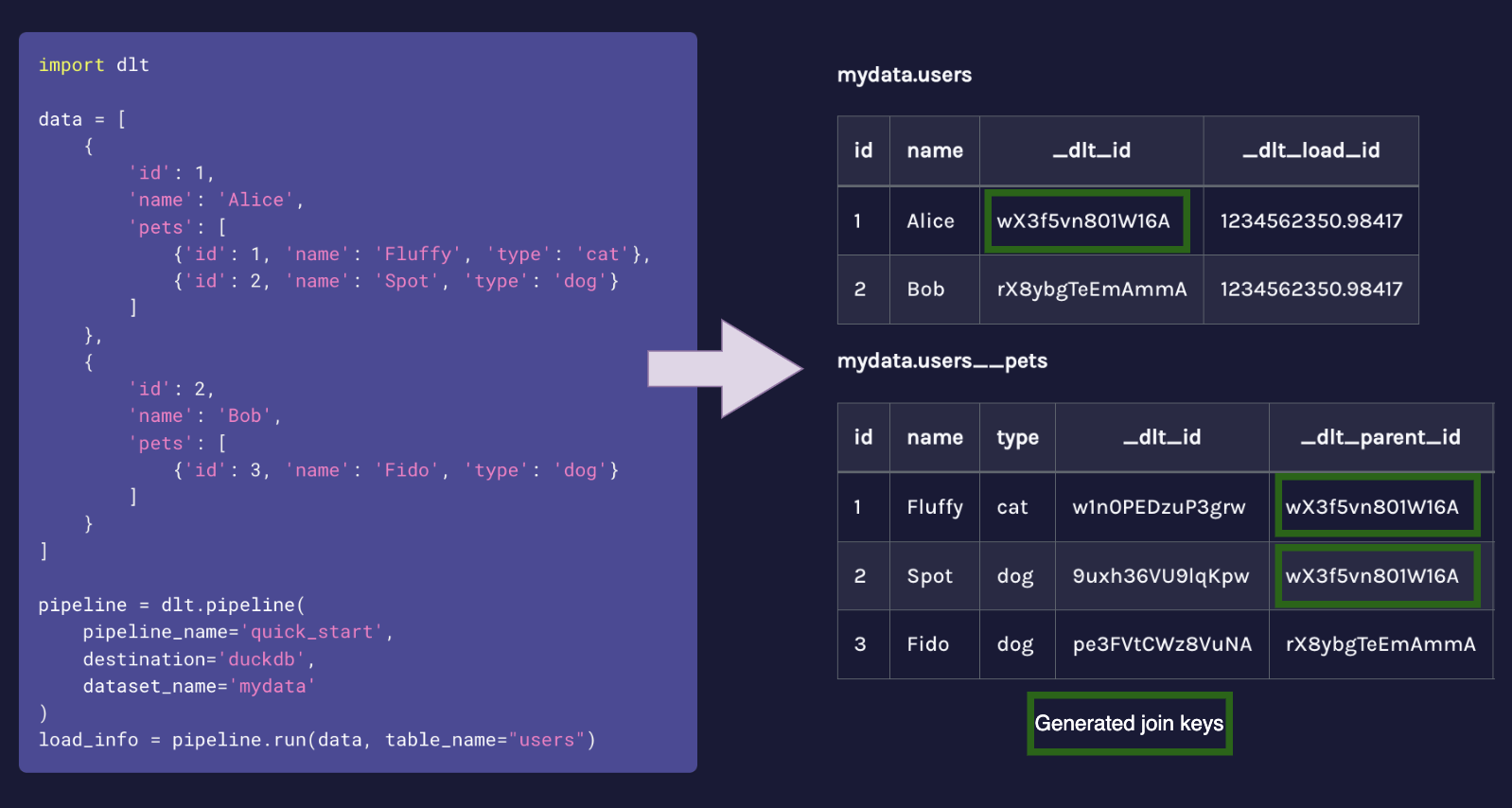
- Wouldn’t it be nice if we could auto-flatten and unpack nested structures into tables with generated join keys?
- Wouldn’t it be nice if data types were properly defined and managed?
- Wouldn’t it be nice if we could load the data incrementally, meaning retain some state to know where to start from?
- Wouldn’t it be nice if this incremental load was bound to a way to do incremental extraction?
- Wouldn’t it be nice if we didn’t run out of memory?
- Wouldn’t it be nice if we got alerted/notified when schemas change?
- Wouldn’t it be nice if schema changes were self healing?
- Wouldn’t it be nice if I could run it all in parallel, or do async calls?
- Wouldn’t it be nice if it ran on different databases too, from dev to prod?
- Wouldn’t it be nice if it offered requests with built in retries for those nasty unreliable apis (Hey Zendesk, why you fail on call 99998/100000?)
- Wouldn’t it be nice if we had some extraction helpers like pagination detection?
Auto typing and unpacking with generated keys:
Performance docs
The initial steps
How did we go about it? At first dlt was created as an engine to iron out its functionality. During this time, it was deployed it in several projects, from startups to enterprises, particularly to accelerate data pipeline building in a robust way.
A while later, to prepare this engine for the general public, we created the current interface on top of it. We then tested it in a workshop with many “Normies” of which over 50% were pre-employment learners.
For the workshop we broke down the steps to build an incremental pipeline into 20 steps. In the 6 hour workshop we asked people to react on Slack to each “checkpoint”. We then exported the slack data and loaded it with dlt, exposing the completion rate per checkpoint. Turns out, it was 100%. Everyone who started, managed to build the pipeline. “This is it!” we thought, and spend the next 6 months preparing our docs and adding some plugins for easy deployment.
III. Launching dlt
We finally launched dlt mid 2023 to the general public. Our initial community was mostly data engineers who had been using dlt without docs, managing from reading code. As we hoped a lot of “normies” are using dlt, too!
dlt = code + docs + Slack support
A product is a sum of many parts. For us dlt is not only the dlt library and interface, but also our docs and Slack community and the support and discussions there.
In the early days of dlt we talked to Sebastian Ramirez from FastAPI who told us that he spends 2/3 of his FastAPI time writing documentation.
In this vein, from the beginning docs were very important to us and we quickly adopted our own docs standard.
However, when we originally launched dlt, we found that different user types, especially Normies, expect different things from our docs, and because we asked for feedback, they told us.
So overall, we were not satisfied to stop there.
"Can you make your docs more like my favorite tool's docs?"
To this end we built and embedded our own docs helper in our docs.
The result? The docs helper has been running for a year and we currently see around 300 questions per day. Comparing this to other communities that do AI support on Slack, that’s almost 2 orders of magnitude difference in question volume by community size.
We think this is a good thing, and a result of several factors.
- Embedded in docs means at the right place at the right time. Available to anyone, whether they use Slack or not.
- Conversations are private and anonymous. This reduces the emotional barrier of asking. We suspect this is great for the many “Normies” / “problem solvers” that work in data.
- The questions are different than in our Slack community: Many questions are around “Setup and configuration”, “Troubleshooting” and “General questions” about dlt architecture. In Slack, we see the questions that our docs or assistant could not answer.
- The bot is conversational and will remember recent context, enabling it to be particularly helpful. This is different from the “question answering service” that many Slack bots offer, which do not keep context once a question was answered. By retaining context, it’s possible to reach a useful outcome even if it doesn’t come in the first reply.
dlt = “pip install and go” - the fastest way to create a pipeline and source
dlt offers a small number of verified sources, but encourages you to build your own. As we mentioned, creating an ad hoc dlt pipeline and source is dramatically simpler compared to other python libraries. Maintaining a custom dlt source in production takes no time at all because the pipeline won't break unless the source stops existing.
The sources you build and run that are not shared back into the verified sources are what we call “private sources”.
By the end of 2023, our community had already built 1,000 private sources, 2,000 by early March. We are now at the end of q2 2024 and we see 5,000 private sources.
Embracing LLM-free code generation
We recently launched additional tooling that helps our users build sources. If you wish to try our python-first dict-based declarative approach to building sources, check out the relevant post.
- Rest api connector
- Openapi based pipeline generator that configures the rest api connector.
Alena introduces the generator and troubleshoots the outcome in 4min:
Community videos for rest api source: playlist.
Both tools are LLM-free pipeline generators. I stress LLM free, because in our experience, GPT can do some things to some extent - so if we ask it to complete 10 tasks to produce a pipeline, each having 50-90% accuracy, we can expect very low success rates.
To get around this problem, we built from the OpenAPI standard which contains information that can be turned into a pipeline algorithmically. OpenAPI is an Api spec that’s also used by FastAPI and constantly growing in popularity, with around 50% of apis currently supporting it.
By leveraging the data in the spec, we are able to have a basic pipeline. Our generator also infers some other pieces of information algorithmically to make the pipeline incremental and add some other useful details.
When generation doesn’t work
Of course, generation doesn’t always work but you can take the generated pipeline and make the final adjustments to have a standard REST API config-based pipeline that won’t suffer from code smells.
The benefit of minimalistic sources
The real benefit of this declarative source is not at building time - A declarative interface requires more upfront knowledge. Instead, by having this option, we enable minimalistic pipelines that anyone could maintain, including non coders or human-assisted LLMs. After all, LLMs are particularly proficient at translating configurations back and forth.
Want to influence us? we listen, so you’re welcome to discuss with us in our slack channel #4-discussions
Towards a paid offering
dlt is an open core product, meaning it won’t be gated to push you to the paid version at some point. Instead, much like Kafka and Confluent, we will offer things around dlt to help you leverage it in your context.
If you are interested to help us research what’s needed, you can apply for our design partnership program, that aims to help you deploy dlt, while helping us learn about your challenges.
Call to action.
If you like the idea of dlt, there is one thing that would help us:
Set aside 30min and try it.
See resource below.
We often hear variations of “oh i postponed dlt so long but it only took a few minutes to get going, wish I hadn’t installed [other tool] which took 2 weeks to set up properly and now we need to maintain or replace”, so don't be that guy.
Here are some notebooks and docs to open your appetite:
- An API pipeline step by step tutorial to build a production pipeline from an api
- A colab demo of schema evolution (2min read)
- Docs: RestClient, the imperative class that powers the REST API source, featuring auto pagination https://dlthub.com/docs/general-usage/http/rest-client
- Docs: Build a simple pipeline
- Docs: Build a complex pipeline
- Docs: capabilities overview hub page
- Community & Help: Slack join link.